2010-07-19
_ swap
http://d.hatena.ne.jp/nishiohirokazu/20100622/1277208908
http://d.hatena.ne.jp/nuc/20100716/p17
via http://twitter.com/gusmachine/status/18840198768
@gusmachine さんいいこと言うなあ…ってのはいいとして。
id:nuc さんは空間使用量が O(N**2) で増えていく、 と書いてあるけど、そうなん? と思ってしまった。 fibonacci の多倍長整数のオーダーが O(N) になるのか。
で…
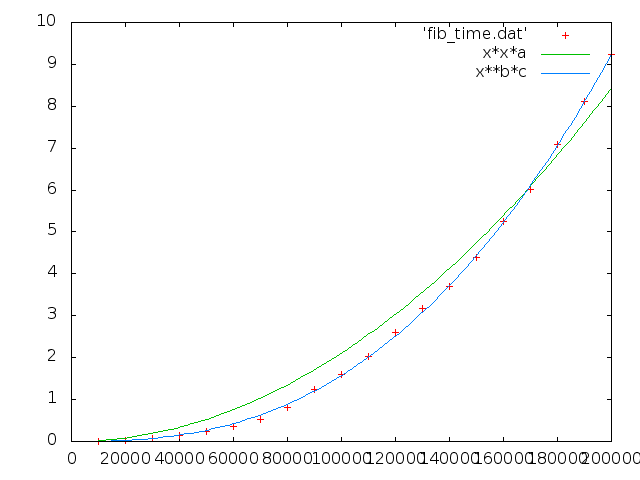
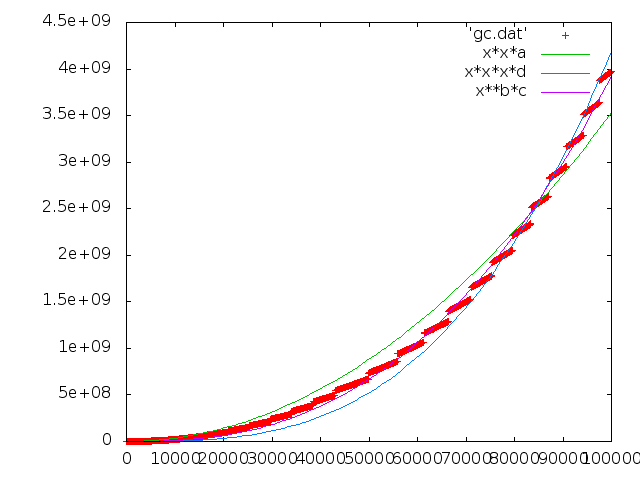
2.77618e-13*x^2.55 の方が 2.10854e-10*x^2 よりどう見てもマッチしてるな。 特異的って感じもないと思う。
まぁ Haskell とか不思議の塊なので、深く考えるのはやめ。
で、メモリ。
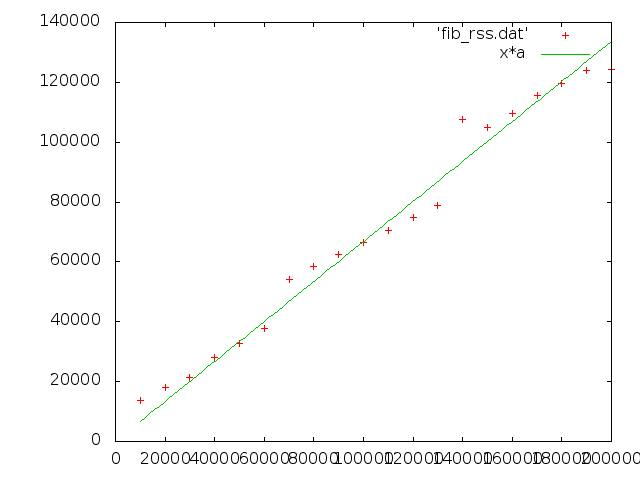
うーん O(N)。
まぁ Haskell とか不思議の塊なので、深く考えるのはやめ…
(02:10)
_ ちなみに
二つ目のグラフの a == 0.668326 だそうです。 そしてメモリの縦軸は kB 。 つまりメモリ使用量が 668 Bytes ずつ増えていく計算になるわけですが…謎。
もう少し上まで
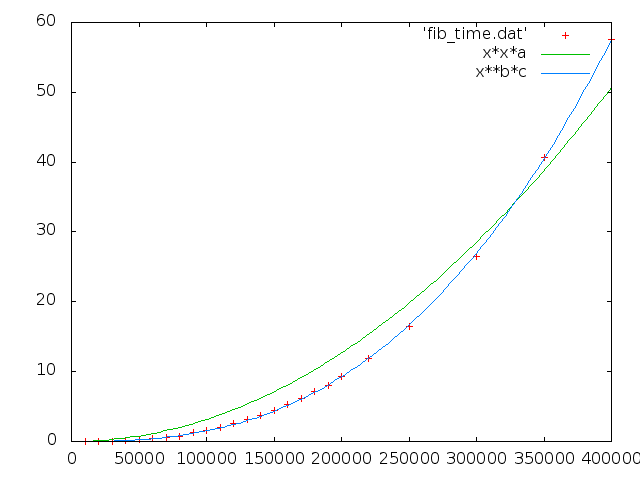
a = 3.16989e-10 +/- 1.038e-11 (3.274%) b = 2.63344 +/- 0.007344 (0.2789%) c = 1.01622e-13 +/- 9.684e-15 (9.53%)
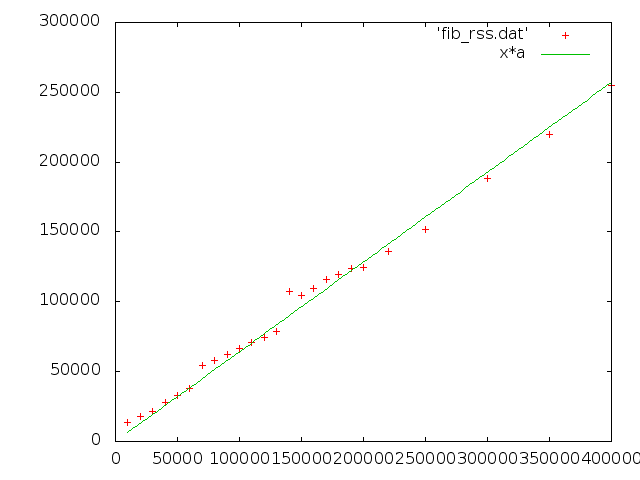
a = 0.642804 +/- 0.007101 (1.105%)
ソースコード
http://github.com/shinh/test/commit/79d93f47d025f841ee9a7639bf3b493d918b86b0
(02:27)
_ wake
名前は
- kati はやっちゃったから hikiwake かなぁ
- てか wake って m ひっくりかえした make っぽいね
- 作りはじめた時に眠かったのに作りたくなって無理矢理起きて作ってた
のでちょうどいいと思った
あと一日中雌豚先生の作業用 BGM 聞いてた結果、 たしかに違うかなーと思った。
(02:42)
_ bf.bef
書いた記憶があるのにどこにもないなぁと探しまわった。
見つかった…
http://d.hatena.ne.jp/shinichiro_h/20100121#1264012341
検索用: befunge brainfuck bfint.bef brainfuck.bef
(02:51)
_ WebKit
たいしたことじゃないけど
http://ss-o.net/webkit/extension/browser.html#Page5
個人的な感覚ではあの switch case は必要悪かなぁ。 分離されてるとかえって不便な気がする。
グローバル変数も過去の遺産っていうか省メモリやら キャッシュしたいやらでしょうがない面も強い、かな。 ただ省メモリ用のハッシュとキャッシュ用の static 変数でのハッシュは、 それぞれ class 作って抽象化しておけば、 いざ thread safe にしたいとか思った時にやりやすかったかもー という意味ではまぁ過去の遺産と言われてもしゃーないか。
http://ss-o.net/webkit/extension/browser.html#Page10
WebKit2 の説明はちょっと意味がわからなかった。 どっちの説明も「なので、」までは正しいと思うんだけど、 後半はどっちもそうなんじゃないか。 WebKit2 もたぶんタスクマネージャ見たら たくさん起動してるだろうし、 どっちも1つのアプリケーションの中でプロセスを分割してるし…?
Chrome は ... なので、使いまわせない。 WebKit2 は ... なので、使いまわせる。 とかがこの文脈で言える唯一のことじゃないかなぁ。
出てきたころは、 WebKit2 はまだ新しいので、 セキュリティうんぬんとか詳しいこと考えてるのかなーとかいうのは 言えたっぽいんだけど、 まぁ今はさっぱり動きとか見てないのでわからない。
(12:56)
_ wake の page
As of September 18, 2010 とか書いてあった。 未来に生きてるなー。
正解は July でした。
さっき昨日ビルドしたはずのファイルに ls -l して、 July とかでてきて、 えーと July って 5 月じゃないかにゃー ヘンだにゃーと思ったところで、 そもそも July は今月だと気付いた。
英語の月名は難しいよなあ…
(13:19)
_ ものはついでと申します
ruby1.9 (git-svn-id: http://svn.ruby-lang.org/repos/ruby/trunk@28675)
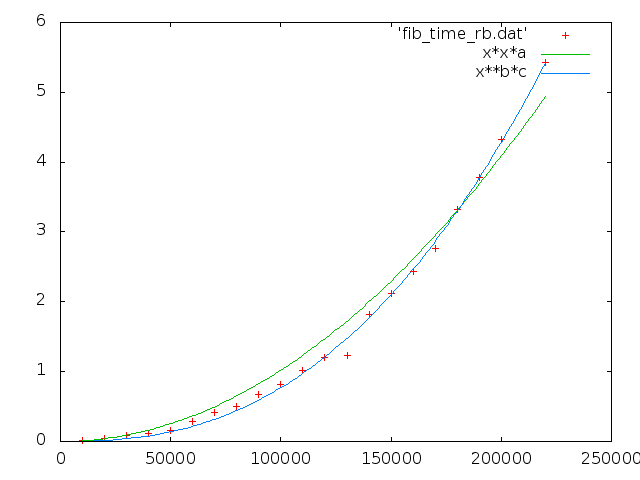
a = 1.02084e-10 +/- 2.187e-12 (2.143%) b = 2.47454 +/- 0.0404 (1.633%) c = 3.26532e-13 +/- 1.625e-13 (49.76%)
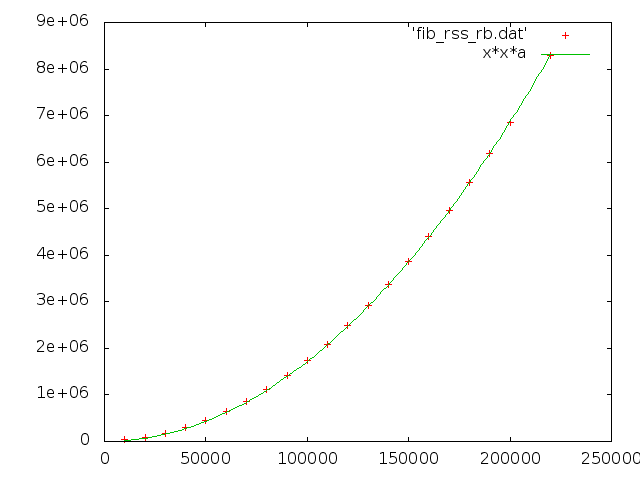
a = 0.642804 +/- 0.007101 (1.105%)
コード
n = ARGV[0].to_i
fib = [1,1]
n.times{|i|
fib << fib[i+1] + fib[i]
}
時間は O(N**2.47454) 。
なにか正直言って、 memory allocator がこんだけ order をいじるんだなぁということを知らなかった。
あと、 Haskell が線型のメモリしか使わないのは、 よく考えたら僕の脳内 Haskell はそいう動きしそうに思ったので、 さして不思議じゃないかなぁと。
java version "1.6.0_18"
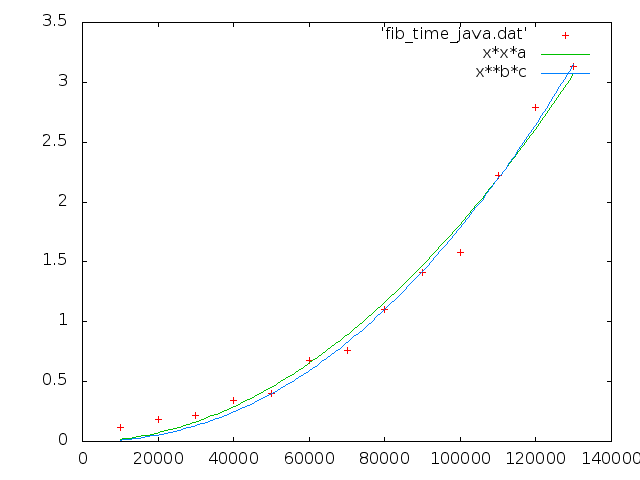
a = 1.81687e-10 +/- 3.693e-12 (2.033%) b = 2.16295 +/- 0.1003 (4.636%) c = 2.73763e-11 +/- 3.232e-11 (118.1%)
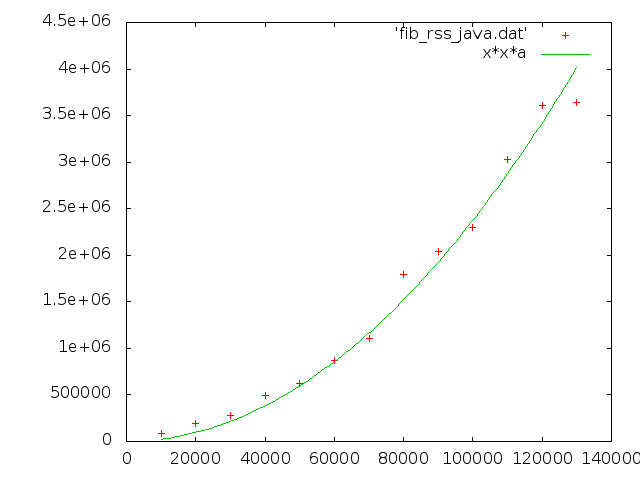
a = 0.000237798 +/- 5.535e-06 (2.328%)
時間は O(N**2.16295) とのことで、 オーダーのオーバヘッドは少ない。 ただそもそもなんか遅いんだけどな…
import java.math.BigInteger;
import java.util.ArrayList;
public class fib {
public static void main(String[] args) {
ArrayList<BigInteger> l = new ArrayList<BigInteger>();
l.add(BigInteger.ONE);
l.add(BigInteger.ONE);
int e = new Integer(args[0]).intValue();
for (int i = 0; i < e; i++) {
l.add(l.get(i).add(l.get(i+1)));
}
}
}
Java 書いたの超ひさしぶりだー
(13:57)
_ C++
完璧言語 C++ ではどうか。
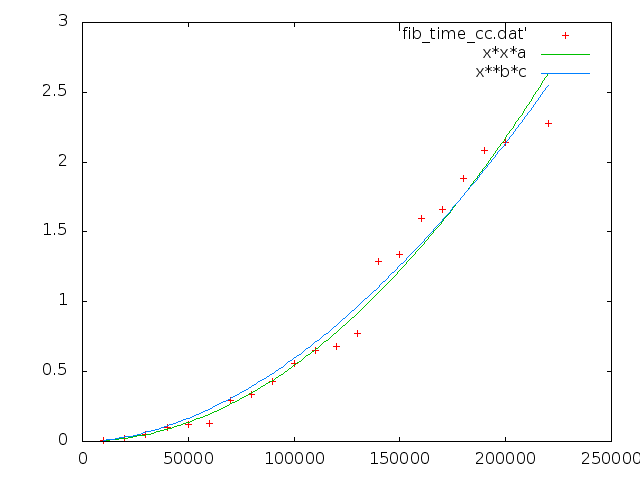
a = 5.4409e-11 +/- 1.265e-12 (2.325%) b = 1.84416 +/- 0.09885 (5.36%) c = 3.58202e-10 +/- 4.327e-10 (120.8%)
O(N**1.84416)! O(N**2) のアルゴリズムのオーダーを減らしてくれる memory allocator! すごいです!!
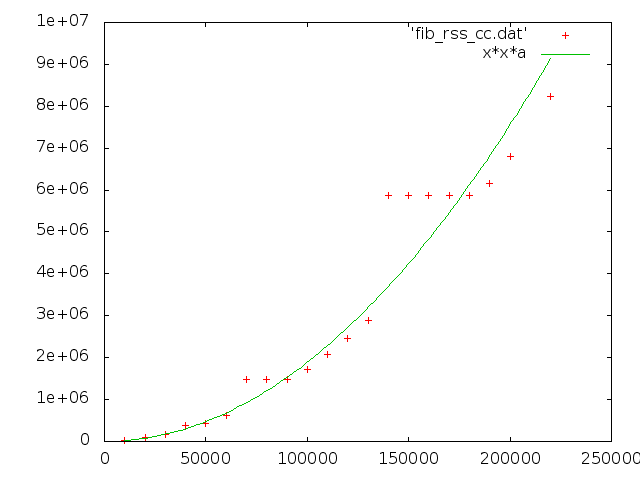
a = 0.000188953 +/- 7.58e-06 (4.011%)
まぁ途中で memory allocator は サイズの大きい小さいで挙動を変えてるだろうし、 gmp もそいうのあるかもしれないし、 まぁ N**a とかでの fit はあまり意味ないんだろうと思う。
ソースコード。 gmpxx ってえらいですね。 GNU とは思えない。知らんかった。
#include <stdio.h>
#include <stdlib.h>
#include <iostream>
#include <vector>
#include <gmp.h>
#include <gmpxx.h>
using namespace std;
int main(int argc, char* argv[]) {
vector<mpz_class> v;
v.push_back(1);
v.push_back(1);
int e = atoi(argv[1]);
for (int i = 0; i < e; i++) {
v.push_back(v[i] + v[i+1]);
}
//cout << v[e] << endl;
}
これまでのあらすじ:
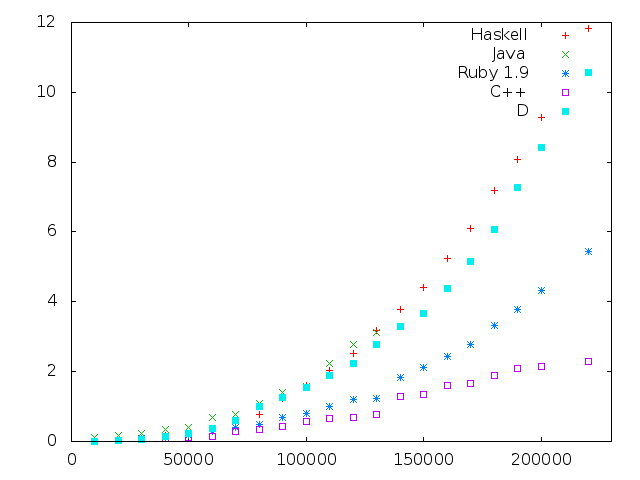
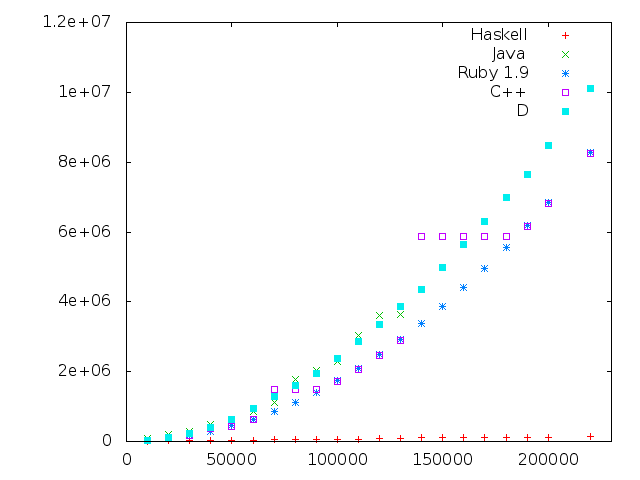
Ruby すごくね
(14:57)
_ あとそうだ
これは GC のある言語に大変厳しいベンチマークなので、 公平性には欠けまくりだと思う。
なんでかっていうとメモリ使用量が増えるばっかりで、 全然 collection されないから。
聞いた話によると、コンパイラとかはこいう挙動をする、 GC 泣かせなアプリの一つらしい。 つまりソースコードを読んでがーとデータ構造作るんだけど、 作るばっかであんま解放する物は無い、というような。
(15:01)
_ Gimite [そういえばSTLのmanってどこにあります?探してみたものの、見つからず…。]
_ yutak [Fedora では libstdc++-docs というパッケージに入ってました 他のディストリでも似たような名前の..]
_ shinh [Debian sid と Ubuntu Hardy では libstdc++6-doc でした。]
_ Gimite [どうもです。Ubuntuでlibstdc++6-4.2-docというのに入ってました。libstdc++6-4.3-..]